엑사원 로고.(사진=LG)
이번 모델은 독자 AI 파운데이션 모델 프로젝트에서 개발 중인 ‘K-엑사원’의 모달리티 확장을 위한 준비 단계다. 연구원은 올해 8월 프로젝트 2차수 종료가 끝나고 3차수 진출이 확정되면 본격적인 모달리티 확장에 나선다.
엑사원 4.5는 △계약서 △기술 도면 △재무제표 △스캔 문서 등 산업 현장에서 실제 다루는 복합 문서를 정확하게 읽고 추론하는 것에 강점이 있다. LG AI연구원은 이와 관련해 멀티모달 AI 모델의 시각 처리와 추론 성능을 평가하는 벤치마크 점수 결과를 공개해 경쟁력을 입증했다.
엑사원 4.5는 STEM(과학·기술·공학·수학) 성능을 측정하는 5개 지표 평균 77.3점을 기록했다. △미국 오픈AI GPT5-mini(73.5점) △앤트로픽 클로드 소넷 4.5(74.6점), △중국 알리바바 큐웬3 235B(77.0점)를 모두 앞선 수준이다.
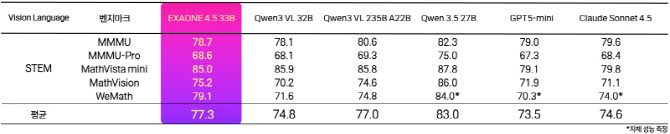
엑사원 4.5 글로벌 동급 모델들과의 STEM 벤치마크 성능 비교.(사진=LG)
아울러 코딩 성능과 관련한 대표 지표 ‘라이브코드벤치 v6’에서는 81.4점을 얻으며 구글의 최신 모델 젬마 4(80.0점)에 앞섰다. 복잡한 차트에 대한 분석·추론 능력을 평가하는 ChartQA Pro에서는 62.2점을 거둬 동급 모델과의 비교에서 글로벌 경쟁력을 입증했다.
엑사원 4.5는 성능과 함께 효율성 측면에서도 주목할 만한 결과를 얻었다. 이번 모델은 330억 개 파라미터 규모(33B)로 지난해 말 공개한 K-엑사원의 약 7분의 1 크기이지만, 텍스트 이해 및 추론에서 동등한 수준의 성능을 달성했다. LG AI연구원이 자체 개발한 하이브리드 어텐션 구조와 멀티 토큰 예측 기반의 고속 추론 기술을 적용한 결과다.
이 외에 LG AI연구원은 공식 지원 언어를 한국어와 영어 외에 스페인어, 독일어, 일본어, 베트남어까지 확장했다.
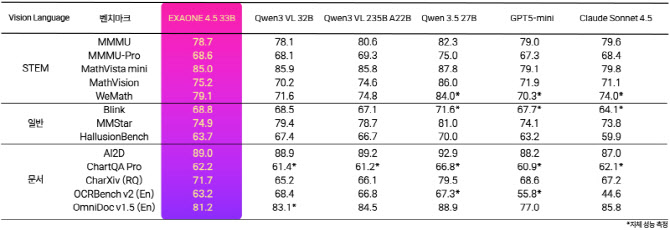
엑사원 4.5 글로벌 동급 모델들과의 벤치마크 성능 비교.(사진=LG)
이진식 LG AI연구원 엑사원랩장은 “이번 모델을 시작으로 음성과 영상, 물리 환경까지 AI의 이해 범위를 확장해 산업 현장에서 실질적으로 판단하고 행동하는 AI를 만들어가겠다”고 밝혔다.
LG AI연구원은 엑사원을 한국의 역사와 문화, 사회적 맥락까지 깊이 이해하는 AI로 발전시키는 데에도 힘쓰고 있다. 올해 1월 동북아역사재단으로부터 데이터를 제공받아 학습을 진행하고 있으며, 고품질 데이터를 보유한 국내 다른 기관들과의 협업을 논의 중이다.
김명신 LG AI연구원 신뢰안전사무국 총괄은 “한국어 능력을 갖춘 AI는 늘고 있지만, 역사와 문화적 민감성을 깊이 이해하는 것은 차원이 다른 문제”라며 “엑사원은 자체 설계한 AI 위험 분류체계(K-AUT)를 기반으로 풍부한 표현력과 신뢰성을 동시에 확보한 AI로 진화해 나갈 것”이라고 말했다.