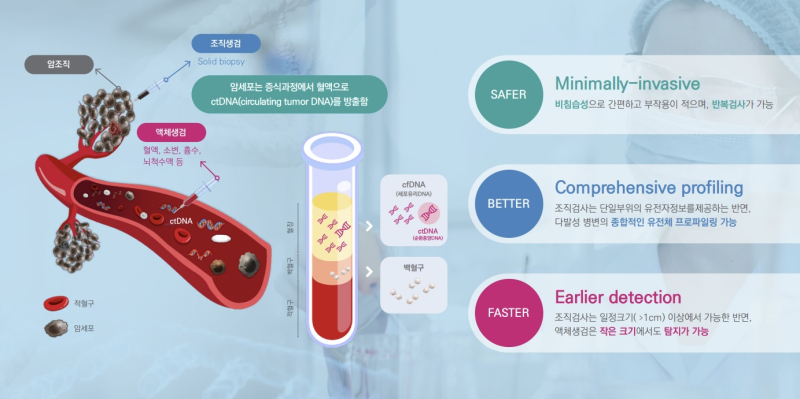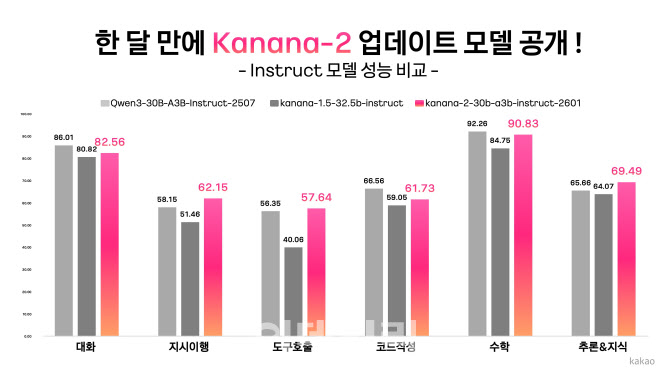
카카오, 업데이트된 ‘Kanana-2’ 모델 4종 오픈소스로 추가 공개(사진=카카오)
핵심 기술은 전문가 혼합(MoE) 구조다. 전체 파라미터는 32B 규모지만, 추론 시 3B만 활성화해 연산 비용을 크게 줄인다. 카카오는 MoE 학습에 필요한 커널을 직접 개발해 학습 속도와 메모리 효율도 확보했다고 설명했다.
학습 과정도 세분화했다. 카카오는 사전학습과 사후학습 사이에 ‘미드 트레이닝(Mid-training)’ 단계를 넣고, 새로운 정보를 학습할 때 기존 능력이 훼손되는 치명적 망각을 막기 위해 ‘리플레이(Replay)’ 기법을 도입했다. 이를 통해 한국어 능력·상식 추론·지시 이행을 동시에 유지하는 균형형 모델을 구현했다는 설명이다.
카카오는 이를 기반으로 △기본(Base) 모델부터 △지시 이행(Instruct) 모델 △추론 특화(Thinking) 모델 △미드 트레이닝 모델까지 총 4종의 모델을 허깅페이스에 추가로 공개했다. 연구자용 미드 트레이닝 탐색 모델까지 포함해 오픈소스 활용도를 높였다.
또 하나의 차별점은 에이전트 AI 대응 능력이다. 카카오는 멀티턴 도구 호출 데이터를 집중 학습해 사용자 지시 이해→도구 선택→실행까지 이어지는 ‘업무 수행형’ 능력을 강화했다고 밝혔다. 실제 벤치마크에서 ‘Qwen-30B-A3B-Instruct-2507’ 대비 지시 이행 정확도·멀티턴 도구 호출·한국어 성능에서 우위를 보였다는 설명이다.
김병학 카카오 카나나 성과리더는 “고가 인프라 없이도 실용적인 에이전트 AI를 구현하기 위한 설계 철학이 반영된 결과”라며 “국내 AI 연구 생태계와 기업 도입의 대안이 되기를 기대한다”고 말했다.
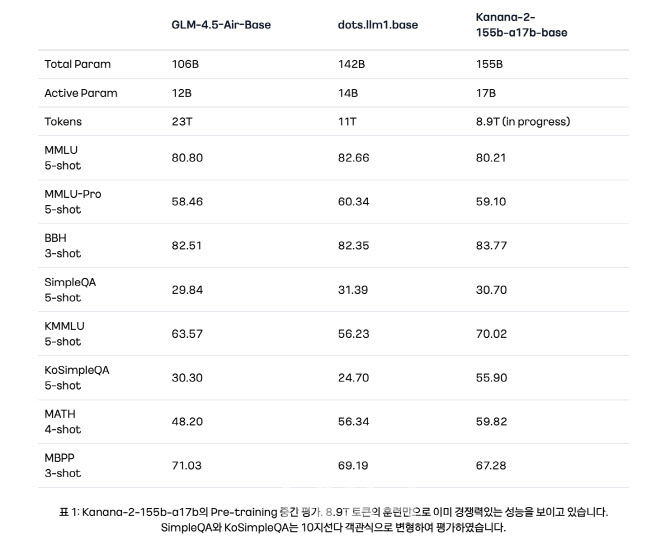
카카오, 업데이트된 ‘Kanana-2’ 모델 4종 오픈소스로 추가 공개(사진=카카오)
카카오는 향후 글로벌 상위 수준의 파운데이션 모델 개발과 더 복잡한 에이전트 시나리오 대응을 목표로 기술 고도화를 이어간다는 계획이다.