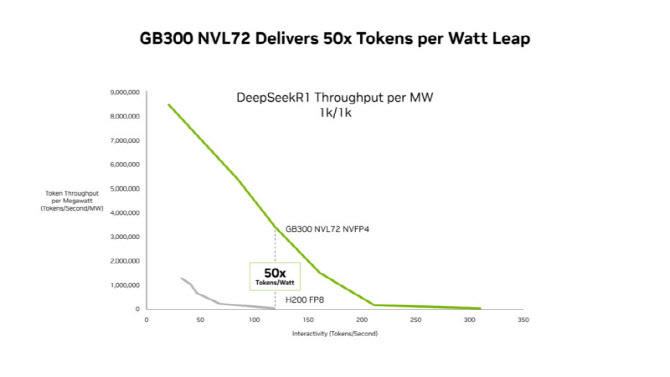
엔비디아는 GB300 NVL72 시스템 기준으로 기존 호퍼(Hopper) 플랫폼 대비 메가와트당 처리량을 최대 50배 높이고, 저지연 환경에서 100만 토큰당 비용을 최대 35배 낮췄다고 밝혔다.
엔비디아는 23일 발표문을 통해 블랙웰 울트라 기반 플랫폼이 에이전틱 AI 추론 성능과 비용 효율성을 크게 개선했다고 설명했다. 특히 마이크로소프트, 코어위브(CoreWeave), 오라클 클라우드 인프라(OCI) 등 주요 클라우드 사업자들이 GB300 NVL72를 에이전틱 코딩, 대화형 코딩 어시스턴트 등 저지연·긴 컨텍스트 워크로드에 적용하고 있다고 전했다.
이번 발표의 핵심은 단순한 칩 성능 경쟁이 아니라 AI 서비스 사업자의 수익성과 직결되는 ‘토큰 경제성’이다. 엔비디아는 블랙웰 플랫폼이 베이스텐(Baseten), 딥인프라(DeepInfra), 파이어웍스 AI(Fireworks AI), 투게더 AI(Together AI) 등 추론 서비스 업체들에 도입되며 토큰당 비용 절감 효과를 내고 있다고 강조했다.
엔비디아, 블랙웰 울트라로 에이전틱 AI 시대 가속 성능 최대 50배비용 35배
토큰(Token)은 생성형 AI가 문장을 처리할 때 나누는 최소 단위다. 단어 전체가 1토큰이 될 때도 있지만, 단어 일부나 조사, 기호 단위로 쪼개지기도 한다. AI 서비스 비용은 통상 입력 토큰과 출력 토큰을 기준으로 산정되기 때문에, 같은 품질의 결과를 더 낮은 토큰 비용으로 제공할수록 사업성이 높아진다. 기사에서 말하는 ‘100만 토큰당 비용’은 AI가 총 100만 개 토큰을 입력·출력 처리하는 데 드는 추론 비용을 뜻한다.
◇에이전틱 AI 확산…저지연·긴 컨텍스트 수요 동시 확대
엔비디아는 에이전틱 AI 확산으로 저지연성과 긴 컨텍스트 처리 능력이 동시에 중요해졌다고 진단했다. 오픈라우터(OpenRouter) 보고서를 인용해, AI 에이전트와 코딩 어시스턴트 확산으로 소프트웨어 프로그래밍 관련 AI 쿼리 비중이 지난해 11%에서 약 50%로 급증했다고 소개했다.
이 같은 워크로드는 다단계 작업 흐름에서 밀리초(ms) 단위 지연이 누적되는 구조여서 응답 지연을 최소화해야 한다. 동시에 대규모 코드베이스 전체를 이해하기 위한 긴 문맥 처리 능력도 요구된다. 결국 고성능과 저비용을 동시에 만족시키는 추론 인프라가 시장 경쟁력을 좌우한다는 설명이다.
◇GB300 NVL72, 저지연 구간서 비용 효율 강화
엔비디아는 세미애널리시스(SemiAnalysis) InferenceX 성능 데이터를 인용해, 소프트웨어 최적화와 블랙웰 울트라 플랫폼의 결합이 저지연 추론 성능과 비용 효율 모두에서 의미 있는 개선을 만들었다고 밝혔다. GB300 NVL72는 호퍼 대비 메가와트당 처리량이 최대 50배 향상됐고, 에이전틱 애플리케이션이 주로 작동하는 저지연 환경에서 100만 토큰당 비용을 최대 35배 절감했다고 했다.
회사는 이러한 개선 배경으로 칩, 시스템 아키텍처, 소프트웨어를 묶은 공동 설계(co-design) 전략을 제시했다. 텐서RT-LLM, 다이나모(Dynamo), 문케이크(Mooncake), SGLang 팀의 최적화가 결합되면서 전 지연 시간 구간에서 MoE(전문가 혼합) 추론 처리량이 크게 높아졌다는 설명이다.
또한 고성능 GPU 커널 최적화, GPU 간 직접 메모리 접근을 지원하는 NVLink 시메트릭 메모리, 이전 커널 종료 전 다음 커널 설정을 진행하는 프로그래매틱 디펜던트 런치 등이 저지연 추론 성능 개선에 기여했다고 덧붙였다.
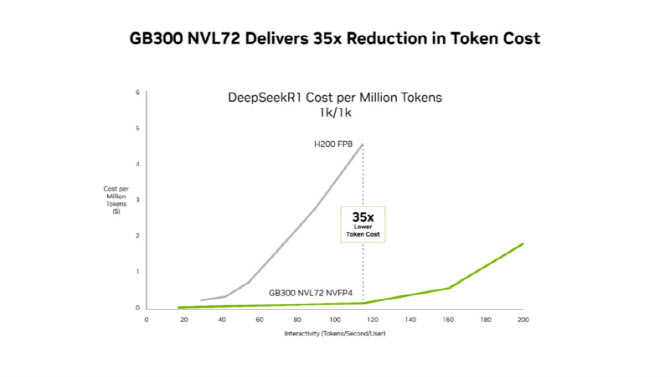
엔비디아 GB300 NVL72, 엔비디아 다이나모, 텐서RT-LLM 등으로 구성된 공동 설계 소프트웨어 스택은 엔비디아 호퍼 플랫폼 대비 토큰당 비용을 35배 절감한다
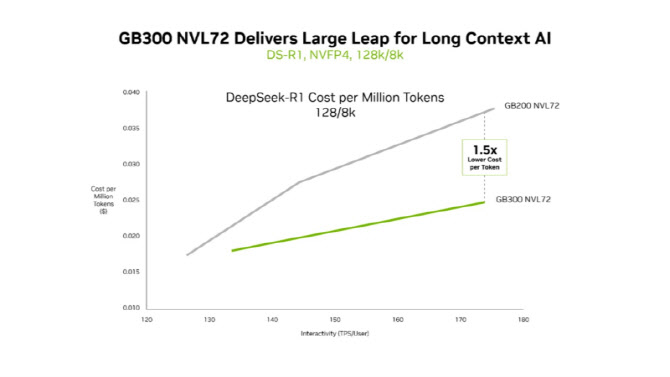
블랙웰 울트라는 긴 컨텍스트 워크로드에서도 비용 경쟁력을 강화했다는 점을 내세웠다. 엔비디아는 12만8000 토큰 입력과 8000 토큰 출력을 처리하는 AI 코딩 어시스턴트형 워크로드를 예시로 들며, GB300 NVL72가 GB200 NVL72 대비 토큰당 비용을 최대 1.5배 낮출 수 있다고 설명했다.
에이전트가 더 많은 코드를 읽을수록 문맥 길이는 늘어나고 연산량도 급증한다. 엔비디아는 블랙웰 울트라가 NVFP4 연산 성능 1.5배, 어텐션 처리 속도 2배 개선을 통해 긴 문맥 기반 추론 효율을 높였다고 밝혔다.
엔비디아는 주요 클라우드 공급업체와 AI 기업들이 GB200 NVL72를 이미 대규모 도입했고, GB300 NVL72도 생산 환경에 투입하고 있다고 밝혔다. 마이크로소프트, 코어위브, OCI가 대표 사례로 제시됐다.
코어위브 측도 발표문에서 추론이 AI 프로덕션 환경의 핵심 요소로 부상하면서 긴 컨텍스트 처리 성능과 토큰 효율성이 중요해졌다고 평가했다. 이는 GPU 성능 자체보다 실제 서비스 운영 비용과 응답 품질을 함께 맞추는 능력이 클라우드 경쟁력의 기준으로 부상하고 있음을 보여준다는 해석이 나온다.
엔비디아 GB300 NVL72는 저지연, 긴 컨텍스트 워크로드에 최적화된 시스템이다
엔비디아는 블랙웰 시스템의 대규모 배포 이후에도 소프트웨어 최적화를 통해 추가 성능 개선과 비용 절감이 이어질 것으로 전망했다. 이어 차세대 루빈(Rubin) 플랫폼에서는 MoE 추론 기준 블랙웰 대비 메가와트당 처리량을 최대 10배 높이고, 100만 토큰당 비용을 10분의 1 수준으로 낮출 수 있다고 제시했다.
결국 이번 발표의 메시지는 분명하다. 에이전틱 AI 시장의 경쟁축이 모델 성능 자체를 넘어, 저지연 응답과 긴 컨텍스트 처리 능력을 얼마나 낮은 토큰 비용으로 제공하느냐로 이동하고 있다는 점이다. 블랙웰 울트라는 그 전환 국면에서 엔비디아의 주도권 강화 카드로 평가된다.









