이번 연구는 Web3와 블록체인 산업 전반에서 대형언어모델(LLM)의 성능을 체계적으로 검증하기 위한 평가 체계를 제시하며, 기존 범용 AI 평가 방식이 산업 전문성을 충분히 반영하지 못한다는 문제를 해결하고자 블록체인 특화 과제를 중심으로 벤치마크를 설계했다.
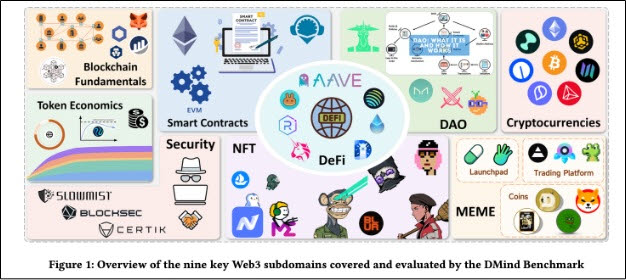
DMind Benchmark 설명표 (사진=DMind 팀)
연구팀은 GPT-5 시리즈, Claude, Gemini, DeepSeek, Grok, Qwen 등 총 31개 주요 AI 모델을 대상으로 성능 비교 평가를 진행했다. 그 결과 GPT-5 Medium이 평균 77.63점으로 가장 높은 점수를 기록했으나, 토큰 이코노믹스와 보안 취약점 영역에서는 다수 모델이 상대적으로 낮은 성능을 보였다. 특히 상용화된 AI 모델들도 Web3 전문 추론 분야에서는 한계를 드러냈으며, 복잡한 토큰 구조 해석이나 스마트 컨트랙트 보안 문제에서는 모델별 성능 차이가 크게 나타났다.
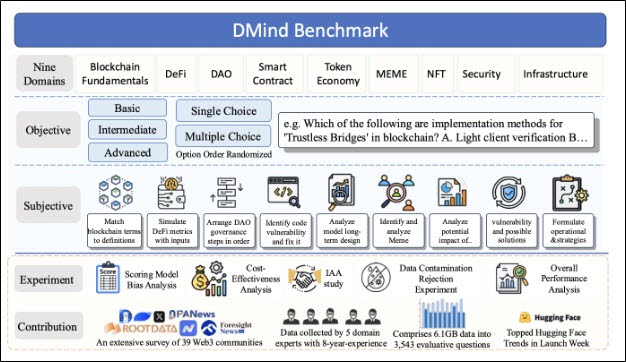
DMind Benchmark 프레임 (사진=DMind 팀)
업계에서는 Web3 기반 서비스 확대와 함께 AI 모델의 신뢰성 검증 중요성이 더욱 커질 것으로 보고 있다. 특히 금융 및 디지털 자산 분야에서는 정확성과 안정성이 핵심 요소로 꼽히는 만큼 산업 특화 평가 체계 구축이 필요하다는 의견이 제기된다. 싱가포르 경영대학교 정보시스템학과 주페이다 교수는 이번 연구가 Web3 AI 분야에서 실질적으로 활용 가능한 평가 기준을 제시했다며, 향후 관련 AI 기술의 안정성과 성능 검증 체계 발전에 기여할 것이라고 평가했다.
한편 DMind 모델은 현재 AI 금융 플랫폼 ‘Minara(미나라)’에 적용돼 운영 중이며, 개인 투자자와 디지털 자산 보유자를 위한 재무 비서 기능 등에 활용되고 있다.