최근 AI PC 성능 경쟁이 단순히 칩 개별 사양을 넘어 GPU, NPU 등 시스템 전체를 아우르는 하드웨어 효율화로 이동하는 가운데, 국내 스타트업이 의미 있는 기술적 돌파구를 마련했다는 평가다.
(사진=노타)
이기종 컴퓨팅은 서로 다른 특성을 가진 프로세서를 유기적으로 결합해 연산 효율을 극대화하는 방식이다. 하나의 프로세서에 전적으로 의존하는 대신, CPU·GPU·NPU가 각자 가장 잘 지연 없이 처리할 수 있는 역할을 나눠 맡도록 설계하는 것이 골자다.
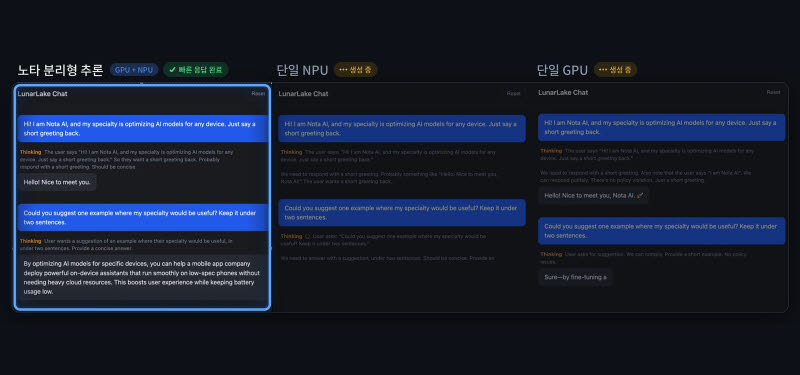
노타는 인텔의 최신 인공지능 칩 ‘루나 레이크(Lunar Lake)’ 기반 AI PC에서 LLM 실행 과정을 △입력 처리와 △답변 생성 등 두 단계로 분리해 분석했다. 이후 각 단계의 특성에 맞춰 연산 장치를 최적 배치하는 ‘분리형 추론(Disaggregated Inference)’ 방식을 적용했다. 연산량이 일시에 몰리는 입력 처리는 GPU에, 지속적인 연산이 필요한 답변 생성은 NPU에 할당하는 방식이다.
성능 평가 결과는 압도적이다. 노타의 분리형 추론 방식을 적용했을 때, 단일 GPU 실행 방식 대비 토큰당 에너지 소비는 약 32% 줄었고, 생성 처리량(Throughput)은 약 12% 향상됐다. 초기 구동 속도를 좌우하는 첫 응답 지연 시간 역시 단일 NPU 실행 방식과 비교해 약 89% 단축됐다.
◇빅테크 분리형 추론 도입 속도...온디바이스 AI 실행효율 높여갈 것
이번 성과는 단순한 하드웨어 병렬 연결이 아니라, AI 모델의 작업 특성을 세부적으로 분석해 최적의 포지셔닝을 찾아냈다는 점에서 주목받는다. 한정된 전력과 자원 안에서 구동해야 하는 ‘온디바이스(On-Device) AI’ 환경에서 사용자 경험(UX)을 결정짓는 핵심 키(Key)가 될 수 있기 때문이다.
실제 글로벌 AI 산업의 지형도 이기종 컴퓨팅과 분리형 추론 중심으로 빠르게 재편되고 있다. 최근 대만에서 개막한 글로벌 IT 박람회 ‘컴퓨텍스(COMPUTEX) 2026’에서도 인텔, 엔비디아 등 글로벌 반도체 공룡들이 CPU·GPU·NPU를 결합한 AI PC 칩셋을 전면에 내세웠다. 데이터센터 영역에서도 엔비디아와 아마존웹서비스(AWS) 등이 AI 연산을 단계별로 나누는 분리형 추론 도입에 속도를 내고 있다.
노타는 이번 기술 구현을 통해 모델 경량화 단계를 넘어, 하드웨어 활용을 극대화하는 ‘풀스택 최적화’ 역량을 입증하게 됐다.
채명수 노타 대표는 “AI PC 시대에는 AI 모델을 기기 안에 올리는 것만으로는 충분하지 않으며 GPU, NPU 등 다양한 연산 장치를 모델 특성에 맞게 조합하는 최적화 역량이 실제 AI 경험을 좌우한다”며, “노타는 모델 경량화, 런타임 최적화, 하드웨어 최적화 기술을 결합해 AI PC 시대의 온디바이스 AI 실행 효율을 높여 나가겠다”고 말했다.









